3.1 Webでの作業方法
普段ホームページを閲覧する際、ブラウザを開くと思います。アドレスを入力してエンターキーを押すと、あなたが見たいコンテンツが表示されます。この見た目には簡単なユーザの行動には一体何が隠されているのでしょうか?
普通のネットワーク上の操作に対して、システムは実はこのように行なっています:ブラウザそのものはクライアントです。URLを入力する際まずブラウザはDNSサーバにアクセスします。DNSを通してドメインと対応するIPを取得し、IPアドレスからIPに対応したサーバを探しだした後、TCPコネクションの設立を要求します。ブラウザがHTTP Request(リクエスト)パケットを送信し終わると、サーバはリクエストパケットを受け取ってリクエストパケットを処理しはじめます。サーバは自分のサービスをコールし、HTTP Response(レスポンス)パケットを返します。クライアントがサーバからのレスポンスを受け取ると、このレスポンスパケットのbodyを読み出します。すべての内容を受け取ると、このサーバとのTCP接続を切断します。
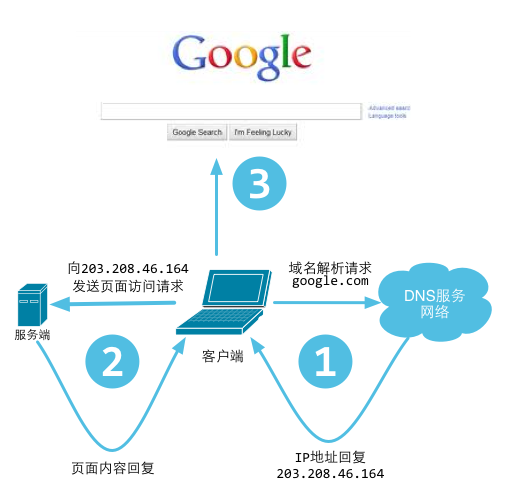
図3.1 ユーザがWebサーバにアクセスする過程
WebサーバはHTTPサーバとも呼ばれます。HTTPプロトコルを通じてクライアントと通信を行います。このクライアントは普通はWebブラウザを指します(実はモバイルクライアントでも内部ではブラウザによって実現されています。)
Webサーバの動作原理は簡単に説明できます:
- クライアントがTCP/IPプロトコルによってサーバまでTCP接続を設立します。
- クライアントはサーバに対してHTTPプロトコルのリクエストパケットを送信し、サーバのリソースドキュメントを要求します。
- サーバはクライアントに対してHTTPプロトコルの応答パケットを送信し、もし要求されたリソースに動的な言語によるコンテンツが含まれている場合、サーバが動的言語のインタープリターエンジンに"動的な内容"の処理をコールさせます。処理によって得られたデータをクライアントに返します。
- クライアントとサーバが切断されます。クライアントはHTMLドキュメントを解釈し、クライアントの画面上に図形として結果を表示します。
簡単なHTTPタスクはこのように実現されます。見た目にはとても複雑ですが、原理はとても簡単です。気をつけなければならないのは、クライアントとサーバの間の通信は常に接続されているわけではありません。サーバが応答を送信した後クライアントと接続が切断され、次のリクエストを待ち受けます。
URLとDNS解決
ホームページの閲覧は常にURLの訪問で行われます。ではURLとは一体どういうものなのでしょうか?
URL(Uniform Resource Locator)は"統一資源位置指定子"の英語の短縮です。ネットワーク上のリソースを表現しています。基本的なシンタックスは以下のとおりです。
scheme://host[:port#]/path/.../[?query-string][#anchor]
scheme 低レイヤーで使用されるプロトコルを指定します。(例えば:http, https, ftp)
host HTTPサーバのIPアドレスまたはドメイン
port# HTTPサーバのデフォルトのポート番号は80です。この場合ポート番号は省略することができます。もし別のポートを使用する場合は指定しなければなりません。例えば http://www.cnblogs.com:8080/
path リソースまでのパス
query-string httpサーバへ送るデータ
anchor アンカー
DNS(Domain Name System)は"ドメインシステム"の英文の省略です。これは組織の木構造の計算機とネットワークサービスの命名システムです。これはTCP/IPネットワークで使用されます。ホスト名またはドメインを実際のIPアドレスに変換する作業を行う役目を担っています。DNSはこのような翻訳家です。この基本的な動作原理は下の図に示しているとおりです。
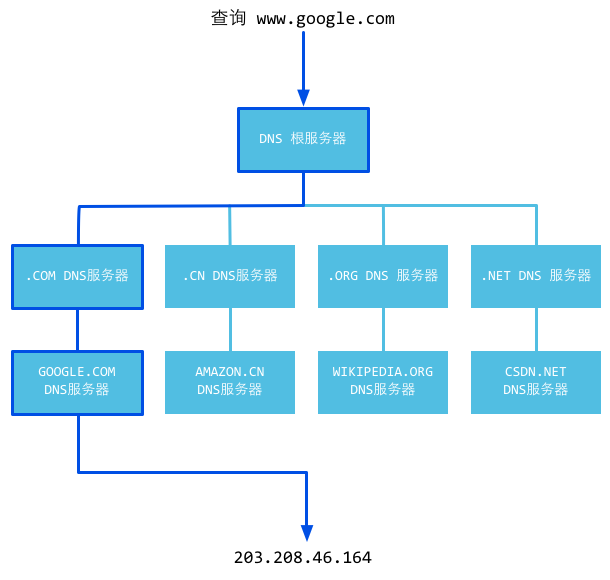
図3.2 DNSの動作原理
より詳細なDNS解決のプロセスは下のようなものです。このプロセスは我々がDNSの作業モードを理解するのに助けとなります。
ブラウザでwww.qq.comドメインを入力します。オペレーティングシステムはまず自分のローカルのhostsファイルにこのアドレスがないか検査します。もしあれば、このIPアドレスの設定が適用されます。ドメイン解決終了。
もしhostsにこのドメインの設定がなければ、ローカルのDNSリゾルバのバッファを探します。もしあれば、これを返します。ドメイン解決終了。
もしhostsとローカルのDNSリゾルバのバッファのどちらにも目的のドメインがなかった場合、まずTCP/IPのオプションで設定されているプライマリDNSサーバを探します。ここではこれをローカルDNSサーバと呼びましょう。このサーバが要求を受けた時、もし要求したドメイン名がローカルで設定されたリソースの中に含まれている場合、解決の結果をクライアントに返します。ドメイン解決終了。これは権威ある解決です。
もし要求したドメイン名がローカルDNSサーバのゾーンでは解決できなかったものの、このサーバがこのURLをバッファリングしていた場合このIPアドレスが適用されます。ドメイン名解決終了。これは権威ある解決ではありません。
もしローカルDNSサーバがそのゾーンファイルとバッファリングのどちらも有効でなかった場合、ローカルDNSサーバの設定に従って(リピータが設定されているか)検査を行います。もし転送モードが使用されていなければローカルDNSはリクエストを"ルートDNSサーバ"に送ります。"ルートDNSサーバ"はリクエストを受け取った後このドメイン名(.com)が誰によって権限を受け管理されているか判断し、このトップレベルドメインの権威サーバのIPを返します。ローカルDNSサーバがIP情報を受け取った後、.comドメインを担当するこのサーバと接続を行います。.comドメインを担当するサーバがリクエストを受け取った後、もし自分で名前解決できなければ、.comドメインを管理するもう一つ下のレイヤーのDNSサーバのアドレス(qq.com)をローカルDNSサーバに送ります。ローカルDNSサーバがこのアドレスを受け取った後、qq.comドメインのサーバを探し出し、www.qq.comのホストが見つかるまで上の動作を繰り返します。
もし転送モードを使用していれば、このDNSサーバはリクエストをひとつ上のレイヤーのDNSサーバに転送します。このサーバが名前解決を行い、名前が解決できなかった場合は、ルートDNSを探すか、もう一つ上のレイヤーのにリクエストを転送します。またはルートが提示されます。最後に結果をローカルDNSサーバに返し、このDNSサーバはクライアントに返します。

図3.3 DNS解決の全体のプロセス
いわゆる
再帰検索プロセスは"検索者"の交代を意味します。また、反復する検索プロセスでは"検索者"は不変です。例をあげて説明しましょう。あなたは一緒に法律の授業を受けている女の子の電話番号を知りたいとします。あなたはこっそり彼女の写真も撮っています。寝室にもどって、正義感の強いアニキたちにそのことを伝えます。このアニキたちは異議を唱えることもなく、胸を叩いてあなたにこう言います。「急ぐ必要はない。私があなたに替わって調べてあげましょう」(この時一時再帰検索が完了しています。すなわち、検索者の役割が変更されました。)。その後彼は写真を携え学部の4年生の先輩のところに聞きにいきます。「この女の子はxx学部なんですけど・・・」その後このアニキは矢継ぎ早にxx学部のオフィス主任の助手を務めているクラスメートに聞きます。このクラスメートはxx学部のyyゼミであると言います。またこの正義感の強いアニキたちはxx学部のyyゼミのゼミ長のところにいき、この女の子の電話番号をゲットします。(ここまでで何回かの連続検索が完了しました。すなわち、検索者の役は変わっていませんが、聞きに行く対象を反復して取り替えています。)最後に彼は番号をあなたの手に渡すことで全体の検索が完了します。
上のステップを通して、IPアドレスを最後に取得します。つまりブラウザが最後にリクエストを送る時はIPにもとづいて、サーバと情報のやりとりをするのです。
HTTPプロトコル詳細
HTTPプロトコルはWeb作業の核心です。そのためWebの作業方法をくまなく理解するためには、HTTPがいったいどのような作業を行なっているのか深く理解する必要があります。
HTTPはWebサーバにブラウザ(クライアント)とInternetを通してデータをやり取りさせるプロトコルです。これはTCPプロトコルの上で成立しますので、一般的にはTCPの80番ポートが採用されます。これはリクエストとレスポンスのプロトコルです--クライアントはリクエストを送信しサーバがこのリクエストに対してレスポンスを行います。HTTPでは、クライアントは常に接続を行いHTTPリクエストを送信することでタスクをこなします。サーバは主導的にクライアントと接続することはできません。また、クライアントに対してコールバック接続を送信することもできません。クライアントとサーバは事前に接続を中断することができます。例えば、ブラウザでファイルをダウンロードする際、"停止"ボタンをクリックすることでファイルのダウンロードを中断し、サーバとのHTTP接続を閉じることができます。
HTTPプロトコルはステートレスです。同じクライアントの前のリクエストと今回のリクエストの間にはなんの対応関係もありません。HTTPサーバからすれば、この2つのリクエストが同じクライアントから発せられたものかすらも知りません。この問題を解決するため、WebプログラムではCookie機構を導入することで、接続の持続可能状態を維持しています。
HTTPプロトコルはTCPプロトコルの上で確立しますので、TCPアタックはHTTPの通信に同じように影響を与えます。例えばよく見かける攻撃として:SYN Floodは現在最も流行したDoS(サービス不能攻撃)とDdoS(分散型サービス不能攻撃)などがあります。これはTCPプロトコルの欠陥を利用して大量に偽造されたTCP接続要求を送信するのです。これにより攻撃された側はリソースが枯渇(CPUの高負荷やメモリ不足)する攻撃です。
HTTPリクエストパケット(ブラウザ情報)
まずRequestパケットの構造を見てみることにしましょう。Requestパケットは3つの部分にわけられます。第一部分はRequest line(リクエスト行)。第二部分はRequest header(リクエストヘッダ)、第三部分はbody(ボディ)と呼ばれます。headerとbodyの間には空行があり、リクエストパケットの例は以下のようなものです。
GET /domains/example/ HTTP/1.1 //リクエスト行:リクエスト方法 リクエストRUI HTTPプロトコル/プロトコルバージョン
Host:www.iana.org //サーバのホスト名
User-Agent:Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.4 (KHTML, like Gecko) Chrome/22.0.1229.94 Safari/537.4 //ブラウザ情報
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 //クライアントが受け取れるmime
Accept-Encoding:gzip,deflate,sdch //ストリーム圧縮をサポートするか否か
Accept-Charset:UTF-8,*;q=0.5 //クライアントの文字コードセット
//空行、リクエストヘッダとボディを分けるために使われます。
//ボディ、リソースへのリクエストのオプション、例えばPOSTが渡すオプション
HTTPプロトコルはサーバに対して交互にリクエストを送る方法が定義されています。基本は四種類。GET,POST,PUT,DELETEです。ひとつのURLアドレスはひとつのネットワーク上のリソースを描写しています。またHTTPの中のGET, POST, PUT, DELETEはこのリソースの検索、修正、増加、削除の4つの操作に対応しています。よく見かけるのはGETとPOSTです。GETは一般的にリソースの情報を取得/検索するために用いられ、POSTはリソース情報を更新するために用いられます。
fiddlerパケットキャプチャを通して下のようなリクエスト情報を見ることができます。
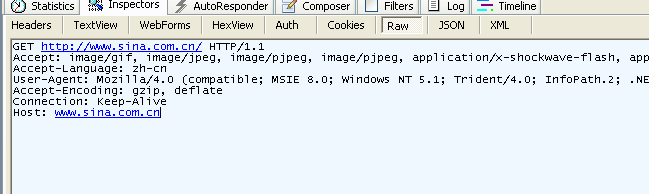
図3.4 fiddlerがキャプチャしたGET情報
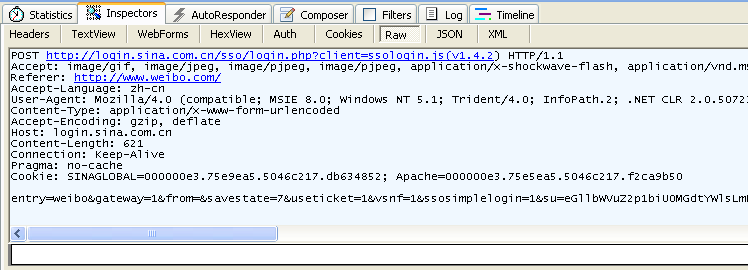
図3.5 fiddlerがキャプチャしたPOST情報
GETとPOSTの区別を見てみましょう。
- GETリクエストのボディが空であることがわかります。POSTリクエストにはボディがあります。
- GETが入力するデータはURLの後に置かれます。?によってURLと渡すデータを分割します。オプションの間は&で繋ぎます。例えばEditPosts.aspx?name=test1&id=12345。POSTメソッドは入力するデータをHTTPパケットのBodyの中に置きます。
- GETが入力するデータの大きさには制限があります。(ブラウザのURLに対する長に制限があるためです。)またPOSTメソッドで入力するデータには制限がありません。
- GETメソッドで入力されたデータはセキュリティの問題を引き起こします。例えばログイン画面があったとして、GETメソッドでデータを入力した場合、ユーザ名とパスワードはURL上にあらわれてしまうことになります。もしページがバッファリングされていたり他の人によっがこのマシンにアクセスすることができれば、ヒストリログからこのユーザのアカウントとパスワードを取得することができてしまいます。
HTTPレスポンスパケット(サーバ情報)
HTTPのresponseパケットを見てみることにしましょう。構造は以下のとおりです:
HTTP/1.1 200 OK //ステータス行
Server: nginx/1.0.8 //サーバが使用するWEBソフトウェアの名称及びバージョン
Date:Date: Tue, 30 Oct 2012 04:14:25 GMT //送信時刻
Content-Type: text/html //サーバが送信するデータの型
Transfer-Encoding: chunked //送信するHTTPパケットが分解されることを表しています。
Connection: keep-alive //コネクション状態の保持
Content-Length: 90 //ボディの内容の長さ
//空行 ヘッダとボディを分けるために使われます。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"... //ボディ
レスポンスパケットの第一行はステータス行と呼ばれ、HTTPプロトコルバージョン番号、ステータスコード、及びステータスメッセージの3つの部分から構成されています。
ステータスコードはHTTPクライアントにHTTPサーバが事前にResponseを発生させるか伝えます。HTTP/1.1プロトコルでは5種類のステータスコードが定義されています。ステータスコードは3桁の数字で表されます。はじめの数字はレスポンスの型を定義しています。
- 1XX 情報の表示 - リクエストの取得に成功しました。継続して処理します。
- 2XX 成功 - リクエストの取得に成功しました。わかりました。受け付けます。
- 3XX リダイレクション - リクエストを完了させる為に一歩進んだ処理が必要です。
- 4XX クライアントエラー - リクエストにシンタックスエラーまたはリクエストを実現できません。
- 5XX サーバーエラー - サーバは合法なリクエストを実現できません。
下の図で詳細なレスポンス情報について説明しております。左側にたくさんのリソースのレスポンスコードを見ることができます。200は通常です。正常なデータであることを意味しています。302ははリダイレクトを意味します。response headerの中には詳細な情報が展開されています。
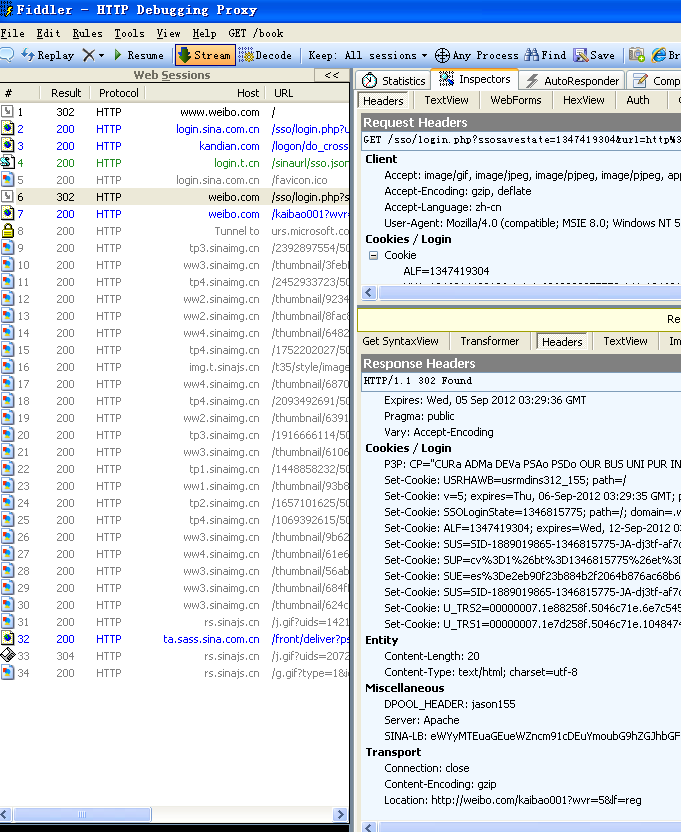
図3.6 ホームページに一度訪問した場合のリクエスト情報のすべて
HTTPプロトコルはステートレスでConnection: keep-aliveの区別
ステートレスとはプロトコルがタスク処理に対して記憶力を有していないことを意味します。サーバはクライアントがどんな状態にあるか知らず、別の角度から言えば、サーバ上のホームページを開いたのと、あなたが以前このサーバ上のホームページを開いた事との間には何の関係もないことを意味しています。
HTTPはステートレスなコネクション指向のプロトコルです。ステートレスとはHTTPがTCP接続を保持していないことを意味するものではありません。また、HTTPがUDPプロトコルを使っていることを示すものでもありません。(コネクションロスに対して)
HTTP/1.1から、デフォルトでKeep-Aliveがオンになっており、接続性が保持されます。簡単にいえば、あるホームページを開き終わった後、クライアントとサーバの間ではHTTPデータを転送するためのTCP接続は閉じません。もしクライアントが再度このサーバ上のホームページを開いた場合、すでに確立されたTCP接続を継続して使用し得ます。
Keep-Aliveは永久にコネクションを保持するものではありません。これには保持する時間があります。異なるサーバソフトウェア(例えばApache)ではこの時間を設定することができます。
リクエスト実例
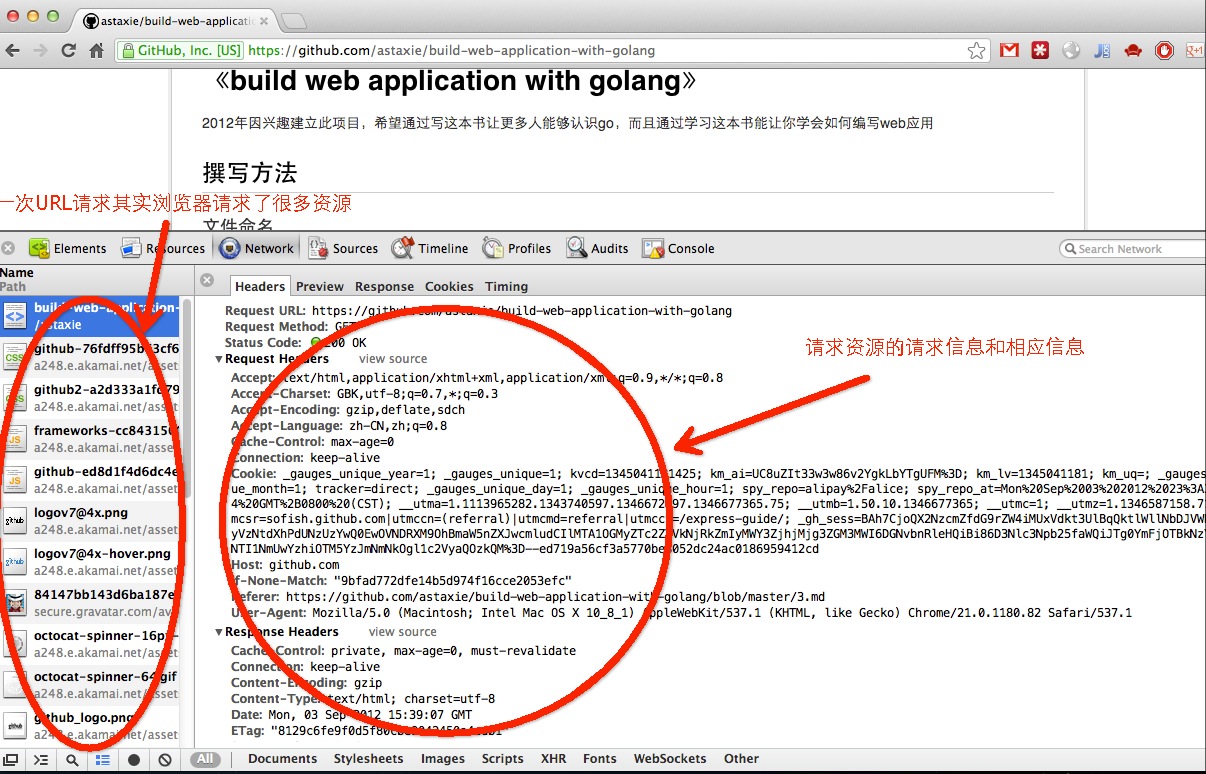
図3.7 一回の要求のrequestとresponse
上の図で全体の通信プロセスをご理解いただけるかと思います。同時に注意深い読者はひとつのURLリクエストにもかかわらず左のペインではどうしてこのように多くのリソース要求があるのかと思われたかもしれません。(これらはすべて静的なファイルです。goは静的なファイルに対して専門的に処理する方法を有しています。)
これはブラウザの機能の一つです。URLを一度要求すると、サーバはhtmlページを返します。その後ブラウザはHTMLを読み取り、HTMLのDOMの中にあるイメージリンク、cssスクリプトとjsスクリプトのリンクを見つけた時、ブラウザは自動的に静的なリソースのHTTP要求を行います。目的の静的なリソースを取得すると、ブラウザは読み始めます。最後にすべてのリソースを整理し、我々の前のスクリーン上に展開します。
ホームページの改良では、HTTPのリクエスト回数を減らすことがあります。つまり、なるべく多くのcssとjsリソースを同じところに集めるのです。目的は出来る限りホームページの静的リソースのリクエスト回数を減少させる事にあります。ホームページの表示速度を上げると同時にサーバのバッファリングを減らす事ができます。
links
- 目次
- 前へ: Webの基礎
- 次へ: GOでWebサーバを建てる