2.3 Control statements and functions
In this section, we are going to talk about control statements and function operations in Go.
Control statement
The greatest invention in programming is flow control. Because of them, you are able to use simple control statements that can be used to represent complex logic. There are three categories of flow control: conditional, cycle control and unconditional jump.
if
if will most likely be the most common keyword in your programs. If it meets the conditions, then it does something and it does something else if not.
if doesn't need parentheses in Go.
if x > 10 {
fmt.Println("x is greater than 10")
} else {
fmt.Println("x is less than or equal to 10")
}
The most useful thing concerning if in Go is that it can have one initialization statement before the conditional statement. The scope of the variables defined in this initialization statement are only available inside the block of the defining if.
// initialize x, then check if x greater than
if x := computedValue(); x > 10 {
fmt.Println("x is greater than 10")
} else {
fmt.Println("x is less than 10")
}
// the following code will not compile
fmt.Println(x)
Use if-else for multiple conditions.
if integer == 3 {
fmt.Println("The integer is equal to 3")
} else if integer < 3 {
fmt.Println("The integer is less than 3")
} else {
fmt.Println("The integer is greater than 3")
}
goto
Go has a goto keyword, but be careful when you use it. goto reroutes the control flow to a previously defined label within the body of same code block.
func myFunc() {
i := 0
Here: // label ends with ":"
fmt.Println(i)
i++
goto Here // jump to label "Here"
}
The label name is case sensitive.
for
for is the most powerful control logic in Go. It can read data in loops and iterative operations, just like while.
for expression1; expression2; expression3 {
//...
}
expression1, expression2 and expression3 are all expressions, where expression1 and expression3 are variable definitions or return values from functions, and expression2 is a conditional statement. expression1 will be executed once before looping, and expression3 will be executed after each loop.
Examples are more useful than words.
package main
import "fmt"
func main(){
sum := 0;
for index:=0; index < 10 ; index++ {
sum += index
}
fmt.Println("sum is equal to ", sum)
}
// Print:sum is equal to 45
Sometimes we need multiple assignments, but Go doesn't have the , operator, so we use parallel assignment like i, j = i + 1, j - 1.
We can omit expression1 and expression3 if they are not necessary.
sum := 1
for ; sum < 1000; {
sum += sum
}
Omit ; as well. Feel familiar? Yes, it's identical to while.
sum := 1
for sum < 1000 {
sum += sum
}
There are two important operations in loops which are break and continue. break jumps out of the loop, and continue skips the current loop and starts the next one. If you have nested loops, use break along with labels.
for index := 10; index>0; index-- {
if index == 5{
break // or continue
}
fmt.Println(index)
}
// break prints 10、9、8、7、6
// continue prints 10、9、8、7、6、4、3、2、1
for can read data from array, slice, map and string when it is used together with range.
for k,v := range map {
fmt.Println("map's key:",k)
fmt.Println("map's val:",v)
}
Because Go supports multi-value returns and gives compile errors when you don't use values that were defined, you may want to use _ to discard certain return values.
for _, v := range map{
fmt.Println("map's val:", v)
}
With go you can as well create an infinite loop, which is equivalent to while true { ... } in other languges.
for {
// your logic
}
switch
Sometimes you may find that you are using too many if-else statements to implement some logic, which may make it difficult to read and maintain in the future. This is the perfect time to use the switch statement to solve this problem.
switch sExpr {
case expr1:
some instructions
case expr2:
some other instructions
case expr3:
some other instructions
default:
other code
}
The type of sExpr, expr1, expr2, and expr3 must be the same. switch is very flexible. Conditions don't have to be constants and it executes from top to bottom until it matches conditions. If there is no statement after the keyword switch, then it matches true.
i := 10
switch i {
case 1:
fmt.Println("i is equal to 1")
case 2, 3, 4:
fmt.Println("i is equal to 2, 3 or 4")
case 10:
fmt.Println("i is equal to 10")
default:
fmt.Println("All I know is that i is an integer")
}
In the fifth line, we put many values in one case, and we don't need to add the break keyword at the end of case's body. It will jump out of the switch body once it matched any case. If you want to continue to matching more cases, you need to use thefallthrough statement.
integer := 6
switch integer {
case 4:
fmt.Println("integer <= 4")
fallthrough
case 5:
fmt.Println("integer <= 5")
fallthrough
case 6:
fmt.Println("integer <= 6")
fallthrough
case 7:
fmt.Println("integer <= 7")
fallthrough
case 8:
fmt.Println("integer <= 8")
fallthrough
default:
fmt.Println("default case")
}
This program prints the following information.
integer <= 6
integer <= 7
integer <= 8
default case
Functions
Use the func keyword to define a function.
func funcName(input1 type1, input2 type2) (output1 type1, output2 type2) {
// function body
// multi-value return
return value1, value2
}
We can extrapolate the following information from the example above.
- Use keyword
functo define a functionfuncName. - Functions have zero, one or more than one arguments. The argument type comes after the argument name and arguments are separated by
,. - Functions can return multiple values.
- There are two return values named
output1andoutput2, you can omit their names and use their type only. - If there is only one return value and you omitted the name, you don't need brackets for the return values.
- If the function doesn't have return values, you can omit the return parameters altogether.
- If the function has return values, you have to use the
returnstatement somewhere in the body of the function.
Let's see one practical example. (calculate maximum value)
package main
import "fmt"
// return greater value between a and b
func max(a, b int) int {
if a > b {
return a
}
return b
}
func main() {
x := 3
y := 4
z := 5
max_xy := max(x, y) // call function max(x, y)
max_xz := max(x, z) // call function max(x, z)
fmt.Printf("max(%d, %d) = %d\n", x, y, max_xy)
fmt.Printf("max(%d, %d) = %d\n", x, z, max_xz)
fmt.Printf("max(%d, %d) = %d\n", y, z, max(y, z)) // call function here
}
In the above example, there are two arguments in the function max, their types are both int so the first type can be omitted. For instance, a, b int instead of a int, b int. The same rules apply for additional arguments. Notice here that max only has one return value, so we only need to write the type of its return value -this is the short form of writing it.
Multi-value return
One thing that Go is better at than C is that it supports multi-value returns.
We'll use the following example here.
package main
import "fmt"
// return results of A + B and A * B
func SumAndProduct(A, B int) (int, int) {
return A + B, A * B
}
func main() {
x := 3
y := 4
xPLUSy, xTIMESy := SumAndProduct(x, y)
fmt.Printf("%d + %d = %d\n", x, y, xPLUSy)
fmt.Printf("%d * %d = %d\n", x, y, xTIMESy)
}
The above example returns two values without names -you have the option of naming them also. If we named the return values, we would just need to use return to return the values since they are initialized in the function automatically. Notice that if your functions are going to be used outside of the package, which means your function names start with a capital letter, you'd better write complete statements for return; it makes your code more readable.
func SumAndProduct(A, B int) (add int, multiplied int) {
add = A+B
multiplied = A*B
return
}
Variadic functions
Go supports functions with a variable number of arguments. These functions are called "variadic", which means the function allows an uncertain numbers of arguments.
func myfunc(arg ...int) {}
arg …int tells Go that this is a function that has variable arguments. Notice that these arguments are type int. In the body of function, the arg becomes a slice of int.
for _, n := range arg {
fmt.Printf("And the number is: %d\n", n)
}
Pass by value and pointers
When we pass an argument to the function that was called, that function actually gets the copy of our variables so any change will not affect to the original variable.
Let's see one example in order to prove what i'm saying.
package main
import "fmt"
// simple function to add 1 to a
func add1(a int) int {
a = a + 1 // we change value of a
return a // return new value of a
}
func main() {
x := 3
fmt.Println("x = ", x) // should print "x = 3"
x1 := add1(x) // call add1(x)
fmt.Println("x+1 = ", x1) // should print "x+1 = 4"
fmt.Println("x = ", x) // should print "x = 3"
}
Can you see that? Even though we called add1 with x, the origin value of x doesn't change.
The reason is very simple: when we called add1, we gave a copy of x to it, not the x itself.
Now you may ask how I can pass the real x to the function.
We need use pointers here. We know variables are stored in memory and they have some memory addresses. So, if we want to change the value of a variable, we must change its memory address. Therefore the function add1 has to know the memory address of x in order to change its value. Here we pass &x to the function, and change the argument's type to the pointer type *int. Be aware that we pass a copy of the pointer, not copy of value.
package main
import "fmt"
// simple function to add 1 to a
func add1(a *int) int {
*a = *a + 1 // we changed value of a
return *a // return new value of a
}
func main() {
x := 3
fmt.Println("x = ", x) // should print "x = 3"
x1 := add1(&x) // call add1(&x) pass memory address of x
fmt.Println("x+1 = ", x1) // should print "x+1 = 4"
fmt.Println("x = ", x) // should print "x = 4"
}
Now we can change the value of x in the functions. Why do we use pointers? What are the advantages?
- Allows us to use more functions to operate on one variable.
- Low cost by passing memory addresses (8 bytes), copy is not an efficient way, both in terms of time and space, to pass variables.
channel,sliceandmapare reference types, so they use pointers when passing to functions by default. (Attention: If you need to change the length ofslice, you have to pass pointers explicitly)
defer
Go has a well designed keyword called defer. You can have many defer statements in one function; they will execute in reverse order when the program executes to the end of functions. In the case where the program opens some resource files, these files would have to be closed before the function can return with errors. Let's see some examples.
func ReadWrite() bool {
file.Open("file")
// Do some work
if failureX {
file.Close()
return false
}
if failureY {
file.Close()
return false
}
file.Close()
return true
}
We saw some code being repeated several times. defer solves this problem very well. It doesn't only help you to write clean code but also makes your code more readable.
func ReadWrite() bool {
file.Open("file")
defer file.Close()
if failureX {
return false
}
if failureY {
return false
}
return true
}
If there are more than one defers, they will execute by reverse order. The following example will print 4 3 2 1 0.
for i := 0; i < 5; i++ {
defer fmt.Printf("%d ", i)
}
Functions as values and types
Functions are also variables in Go, we can use type to define them. Functions that have the same signature can be seen as the same type.
type typeName func(input1 inputType1 , input2 inputType2 [, ...]) (result1 resultType1 [, ...])
What's the advantage of this feature? The answer is that it allows us to pass functions as values.
package main
import "fmt"
type testInt func(int) bool // define a function type of variable
func isOdd(integer int) bool {
return integer%2 != 0
}
func isEven(integer int) bool {
return integer%2 == 0
}
// pass the function `f` as an argument to another function
func filter(slice []int, f testInt) []int {
var result []int
for _, value := range slice {
if f(value) {
result = append(result, value)
}
}
return result
}
var slice = []int{1, 2, 3, 4, 5, 7}
func main() {
odd := filter(slice, isOdd)
even := filter(slice, isEven)
fmt.Println("slice = ", slice)
fmt.Println("Odd elements of slice are: ", odd)
fmt.Println("Even elements of slice are: ", even)
}
It's very useful when we use interfaces. As you can see testInt is a variable that has a function as type and the returned values and arguments of filter are the same as those of testInt. Therefore, we can have complex logic in our programs, while maintaining flexibility in our code.
Panic and Recover
Go doesn't have try-catch structure like Java does. Instead of throwing exceptions, Go uses panic and recover to deal with errors. However, you shouldn't use panic very much, although it's powerful.
Panic is a built-in function to break the normal flow of programs and get into panic status. When a function F calls panic, F will not continue executing but its defer functions will continue to execute. Then F goes back to the break point which caused the panic status. The program will not terminate until all of these functions return with panic to the first level of that goroutine. panic can be produced by calling panic in the program, and some errors also cause panic like array access out of bounds errors.
Recover is a built-in function to recover goroutines from panic status. Calling recover in defer functions is useful because normal functions will not be executed when the program is in the panic status. It catches panic values if the program is in the panic status, and it gets nil if the program is not in panic status.
The following example shows how to use panic.
var user = os.Getenv("USER")
func init() {
if user == "" {
panic("no value for $USER")
}
}
The following example shows how to check panic.
func throwsPanic(f func()) (b bool) {
defer func() {
if x := recover(); x != nil {
b = true
}
}()
f() // if f causes panic, it will recover
return
}
main function and init function
Go has two retentions which are called main and init, where init can be used in all packages and main can only be used in the main package. These two functions are not able to have arguments or return values. Even though we can write many init functions in one package, I strongly recommend writing only one init function for each package.
Go programs will call init() and main() automatically, so you don't need to call them by yourself. For every package, the init function is optional, but package main has one and only one main function.
Programs initialize and begin execution from the main package. If the main package imports other packages, they will be imported in the compile time. If one package is imported many times, it will be only compiled once. After importing packages, programs will initialize the constants and variables within the imported packages, then execute the init function if it exists, and so on. After all the other packages are initialized, programs will initialize constants and variables in the main package, then execute the init function inside the package if it exists. The following figure shows the process.
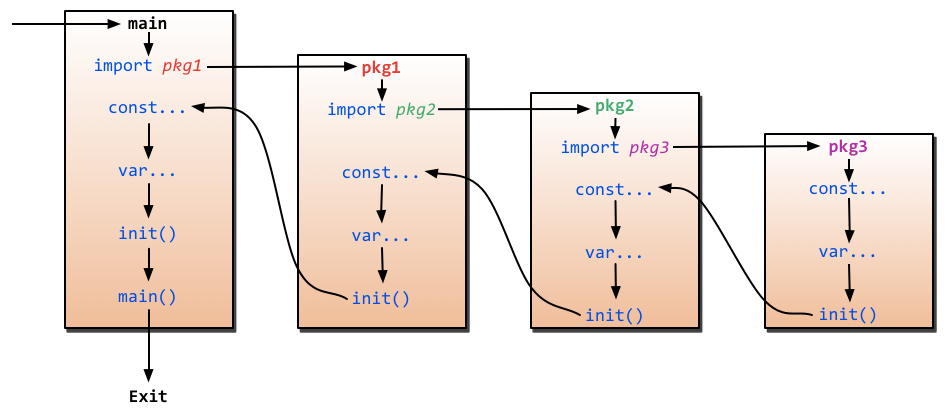
Figure 2.6 Flow of programs initialization in Go
import
We use import very often in Go programs as follows.
import(
"fmt"
)
Then we use functions in that package as follows.
fmt.Println("hello world")
fmt is from Go standard library, it is located within $GOROOT/pkg. Go supports third-party packages in two ways.
- Relative path import "./model" // load package in the same directory, I don't recommend this way.
- Absolute path import "shorturl/model" // load package in path "$GOPATH/pkg/shorturl/model"
There are some special operators when we import packages, and beginners are always confused by these operators.
- Dot operator.
Sometime we see people use following way to import packages.
import( . "fmt" )fmt.Printf("Hello world")becomes toPrintf("Hello world"). - Alias operation.
It changes the name of the package that we imported when we call functions that belong to that package.
import( f "fmt" )fmt.Printf("Hello world")becomes tof.Printf("Hello world"). _operator. This is the operator that is difficult to understand without someone explaining it to you.import ( "database/sql" _ "github.com/ziutek/mymysql/godrv" )_operator actually means we just want to import that package and execute itsinitfunction, and we are not sure if we want to use the functions belonging to that package.
Links
- Directory
- Previous section: Go foundation
- Next section: struct